Graph all the things
analyzing all the things you forgot to wonder about
Map Projections 2: Solving Numerically
2024-02-21
interests: maps, linear algebra, machine learning
In part 1, I explained the problem of solving an optimal map projection and why we can't do it by hand. Now I'll show how I went about solving numerically and give a few teaser visualizations of the projections I designed. Results to come in the following parts!
Lore
I'm fascinated by the remote parts of the world: Baffin Island in the extreme north, Vinson Massif in the south, and the Amazon near the equator. But our map projections often make the poles look huge and shapeless while the equator is unfairly compressed.
When I planned a trip to Peru several years ago, I expected it to be about the size of California. I thought I might cover the coast, Amazon, and desert in just a week and a half. But no, the Mercator projection had deceived me; Peru is 3 times as large as California. Take a look at Google's web Mercator projection (left) vs. an actual size comparison (right):
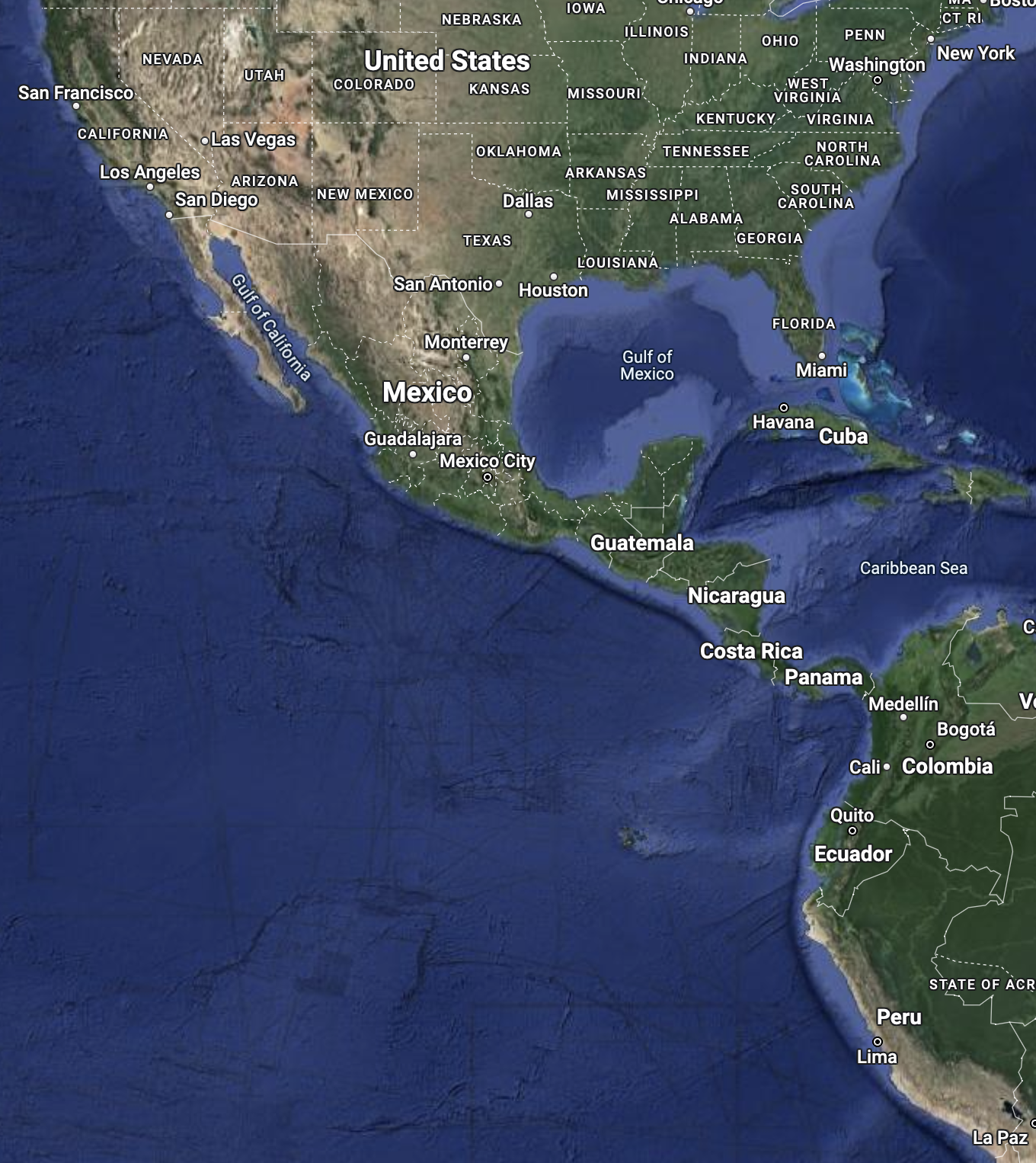
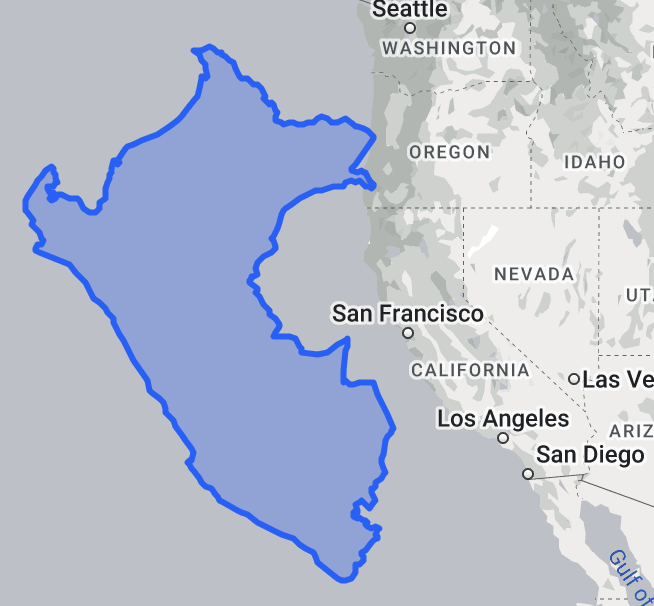
Well, it does make sense for mapping software to use Mercator. It's computationally efficient to work with, and most importantly, it's conformal (preserves local angles everywhere). When you're giving people driving directions, it's pretty important that right angles in Alaska still look like right angles.
But my goal with designing map projections is to convey the size and shape of the planet's features as accurately as possible. That means striking a good compromise at preserving areas and angles, since doing both exactly is impossible. As non-goals: I have no interest in making lines of latitude or longitude straight, or auxiliary objectives like that.
Discretizing the globe
I made a lattice of 6,000 triangles over the globe, connecting 3,044 points. Each of these triangles has 3 angles (duh) for 18,000 angles in total. In the end, I'll sum my (weighted) local loss function evaluated at each angle.
You can see the lattice is a bit quirky, but that helps it achieve balance:
- The points are spaced so that each triangle has roughly equal area. That is,
rows of points are (by default) separated by a fixed distance
 in the z
coordinate and a fixed angle
in the z
coordinate and a fixed angle  in
in  .
. - Near the poles, I increase and decrease ; cutting the number of
points per row, but increasing the number of rows.
Without this, the aspect ratio of some triangles would be too long
and skinny, and polar regions would lack meaningful detail.
Here's a close-up of the north pole, showing how the number of points per row cuts in half and the density of rows increases. The blue area has 50 points per row, green is a transition, and red has 25 points per row (but denser rows).

Due to topology, every map projection must have at least one interruption - one point that appears at least twice in the map. Take a look at this azimuthal projection from Wikipedia, which manages to only interrupt at the south pole:
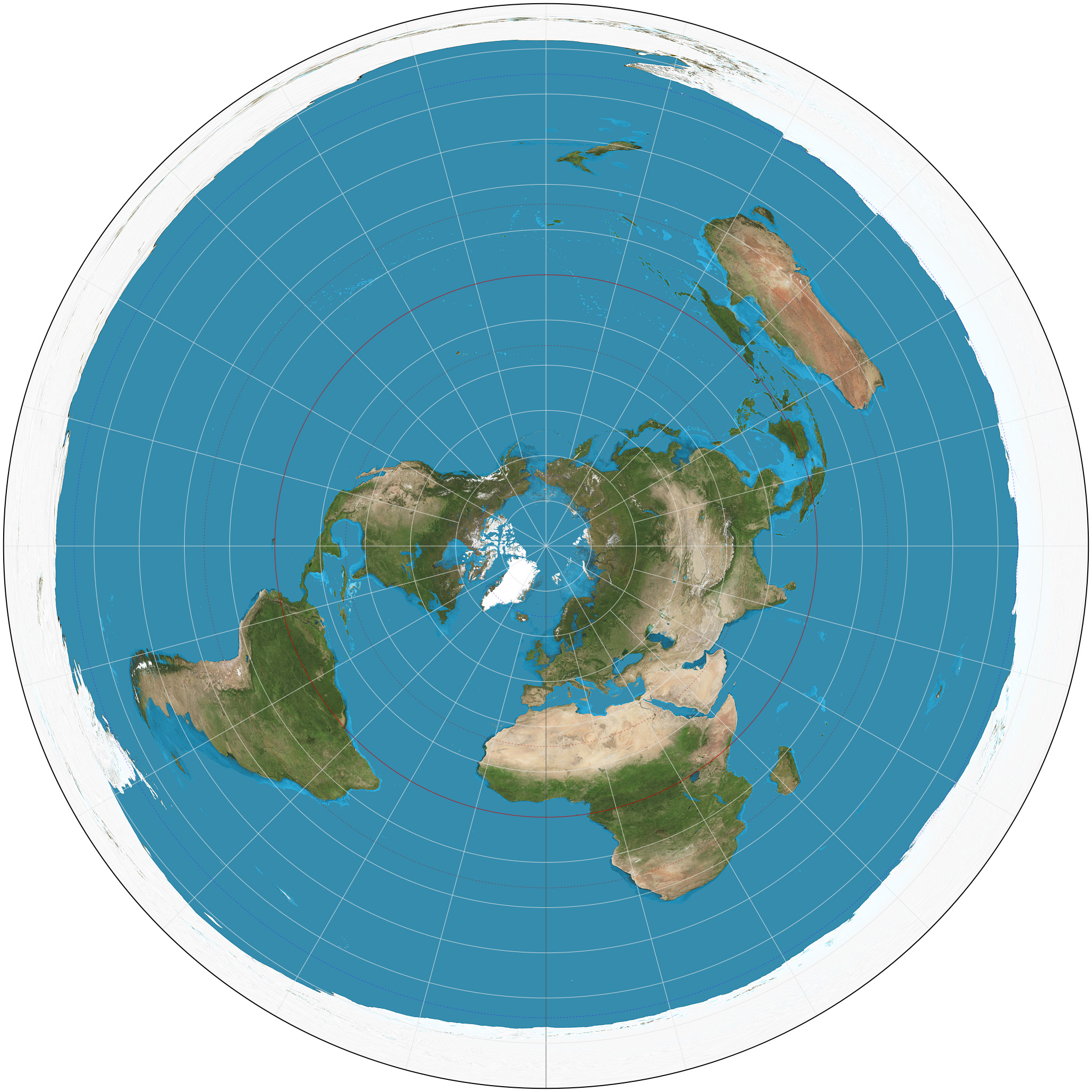
But most famous map projections interrupt the whole antimeridian in the Pacific ocean, including the poles.
I took a familiar but subtly different approach: I interrupt at the antimeridian, but excluding the poles. Therefore each non-pole point on the antimeridian has 2 copies: one for the western hemisphere, and one for the eastern. The extra copy isn't visible in my lattice diagrams, but it's there. Crossing the 180th line of longitude will therefore instantly transport you from the left side of the projection to the right. Many map projections interrupt the poles by converting them into lines, but I think that's a poor way to communicate shape. Points are points in my projections. Some other projections that do this are Mollweide and Hammer.
Transductive model
Most machine learning models you hear about are inductive. Using specific examples, they learn a general rule that converts from inputs to outputs. For instance, a cat vs. dog model may learn from 100,000 images and then be capable of classifying the practically infinite set of possible images.
But instead of an inductive model, I chose a transductive one, directly learning the output (projected xy coordinate) for each of my inputs (point on the sphere). Generalization just wasn't necessary for this application. The sphere is the only domain I care about. Plus, I didn't want to constrain myself to a parametrized model. By making every coordinate a parameter, I can learn any possible projection.
So technically, my "nonparametric" model has  parameters;
x and y coordinates for each point.
parameters;
x and y coordinates for each point.
Loss function
This is an interesting part!
I'm measuring a local distortion at a point  as the
Jacobian
as the
Jacobian  of the projection from the sphere to the plane.
To be clear: the Jacobian is computed using a local coordinate system with
orthonormal basis vectors around , not from spherical coordinates.
of the projection from the sphere to the plane.
To be clear: the Jacobian is computed using a local coordinate system with
orthonormal basis vectors around , not from spherical coordinates.
This matrix has extremely useful singular values  and
and  .
(The unofficial part 0 to this series,
6 Matrix Decompositions Everyone* Should Know,
explains the singular value decomposition.)
.
(The unofficial part 0 to this series,
6 Matrix Decompositions Everyone* Should Know,
explains the singular value decomposition.)

The product  of 's singular values is the ratio by which
the projection
enlarges or shrinks areas, and the ratio
of 's singular values is the ratio by which
the projection
enlarges or shrinks areas, and the ratio  of its singular
values is related to the angular distortion.
An angle on the sphere can differ from its projected counterpart by no more
than
of its singular
values is related to the angular distortion.
An angle on the sphere can differ from its projected counterpart by no more
than
 radians.
Each of these measures ( and ) should
ideally be 1.
radians.
Each of these measures ( and ) should
ideally be 1.
By my reckoning, making something  times too big is just as bad as making it
times too small.
Therefore, I applied the convex loss function
times too big is just as bad as making it
times too small.
Therefore, I applied the convex loss function  to each of these measures.
I weighted them with some hyperparameter
to each of these measures.
I weighted them with some hyperparameter  and added them, giving
and added them, giving

I summed this over each angle of triangle on the lattice, weighting by the product of the triangle's area and the angle. In this way, all lattice points get 360 degrees of angular weight, and all triangles get weight (almost exactly) in proportion to their area.
Optimization method
Grossly simplifying, there are 3 categories of optimization methods:
- those where there's a simple mathematical structure to work with, such as a linear least squares problem,
- those without a simple structure but where you can take gradients of the loss with respect to the model parameters, and
- those where you can't even take gradients.
This problem falls into category 2. The loss function is complicated but differentiable, so gradient descent was a natural choice.
In particular, I used full-batch gradient descent with the Adam optimizer. Adam is an adaptive optimizer that adjusts per-parameter learning rate based on how noisy the recent gradients have been. I'm normally wary of adaptive optimizers, since they have peculiar dynamics which might not converge to a local minimum, no matter how small you set your learning rate. But in this case, Adam was overwhelmingly better than a plain gradient descent optimizer, since the loss was so much more sensitive to some coordinates than others.
See the difference over 600 iterations of training with tuned (non-exploding) learning rate:
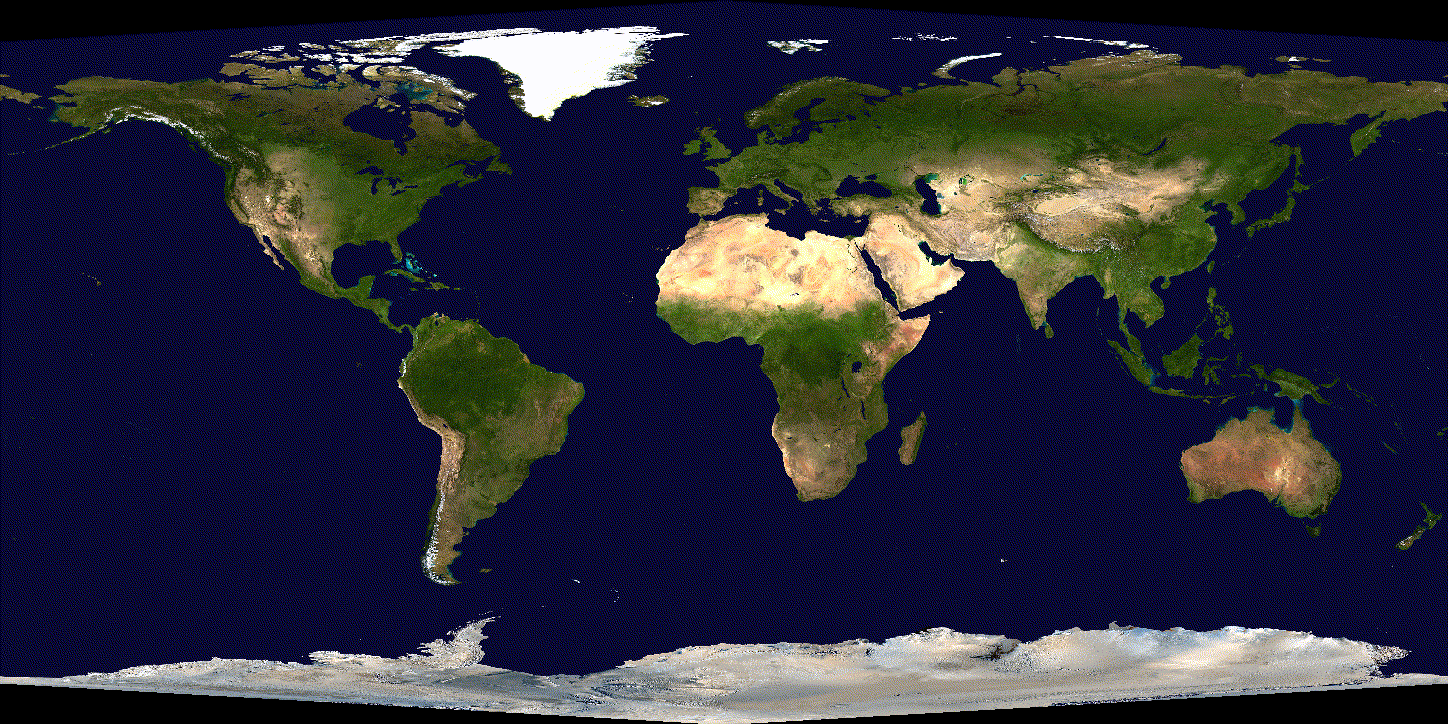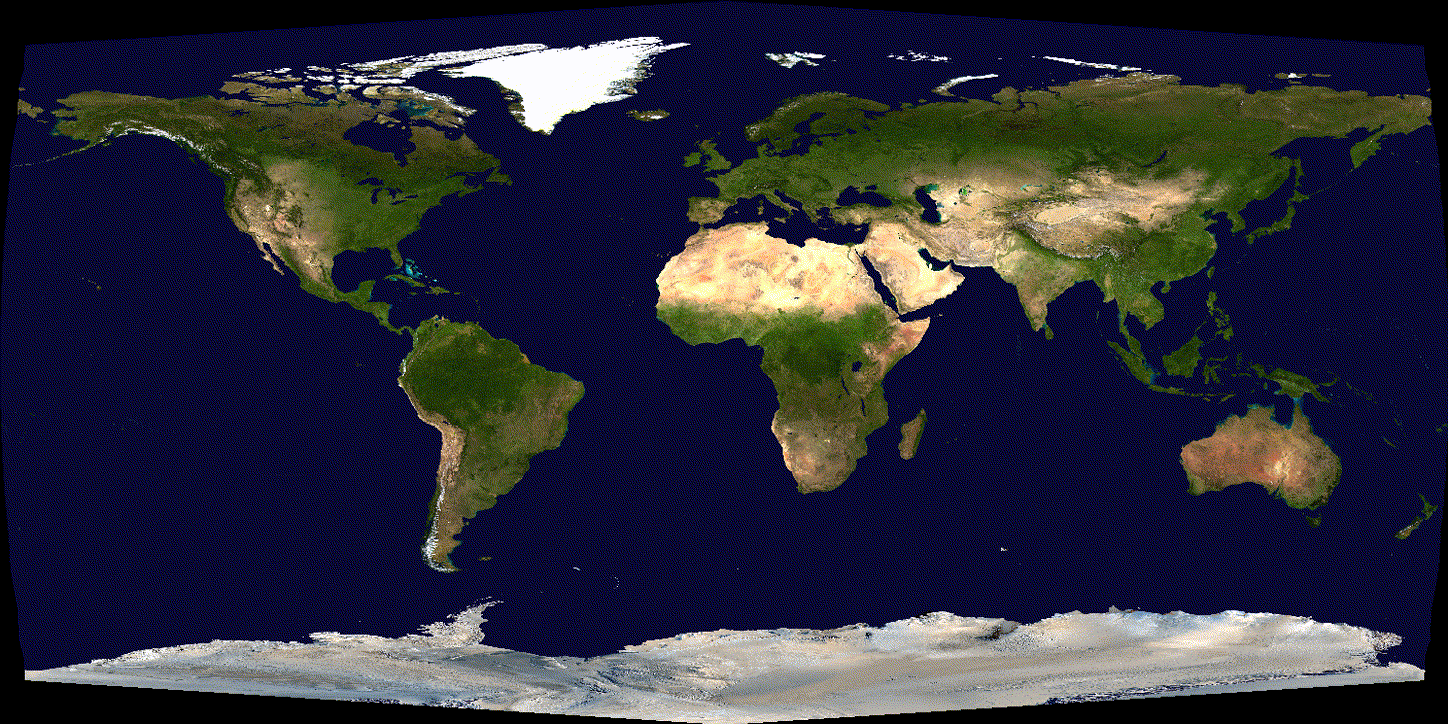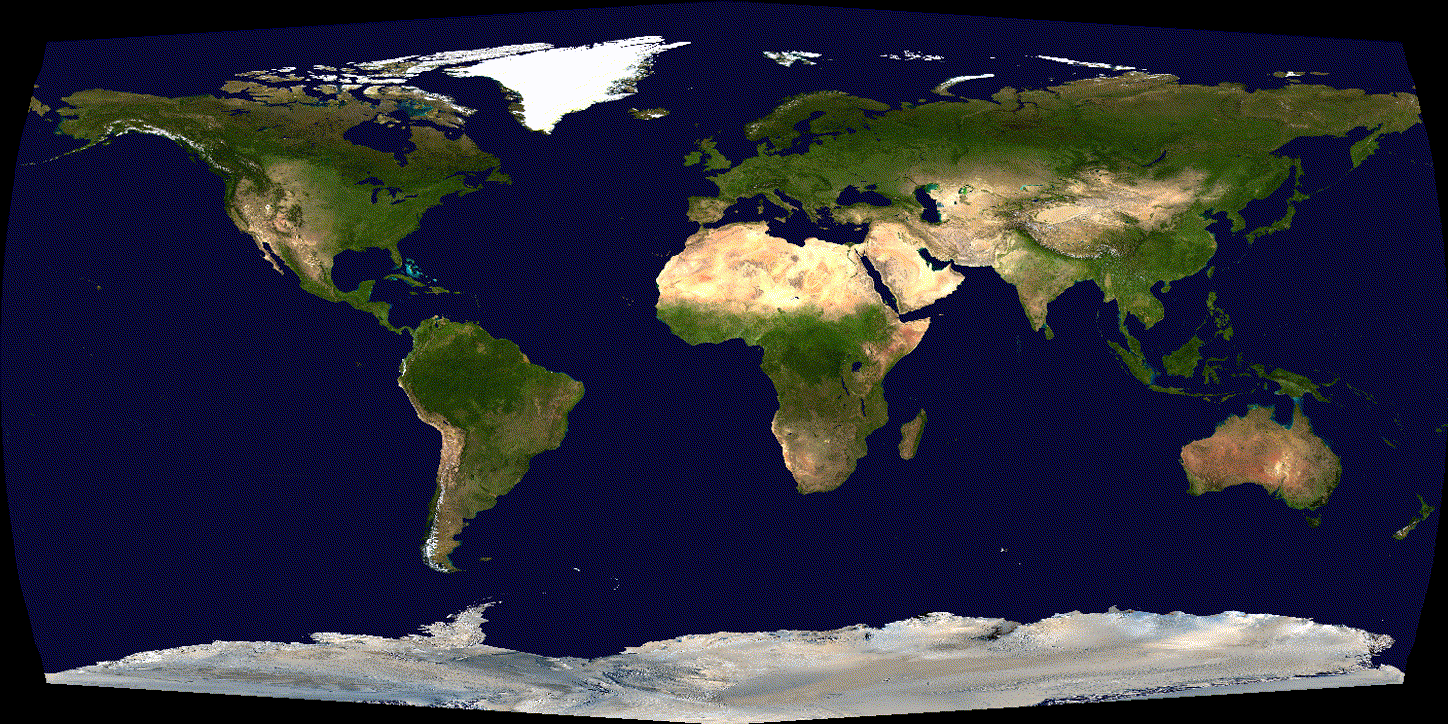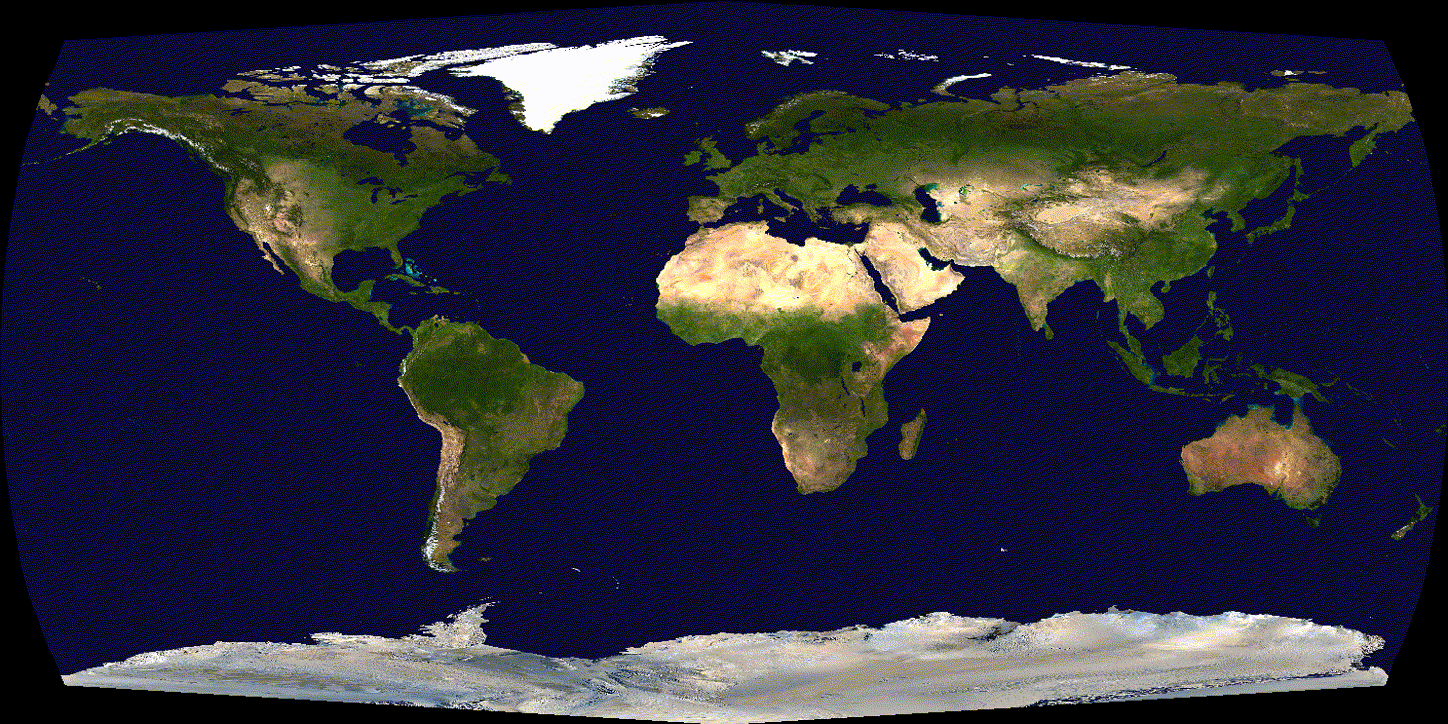 (SGD)
(SGD)
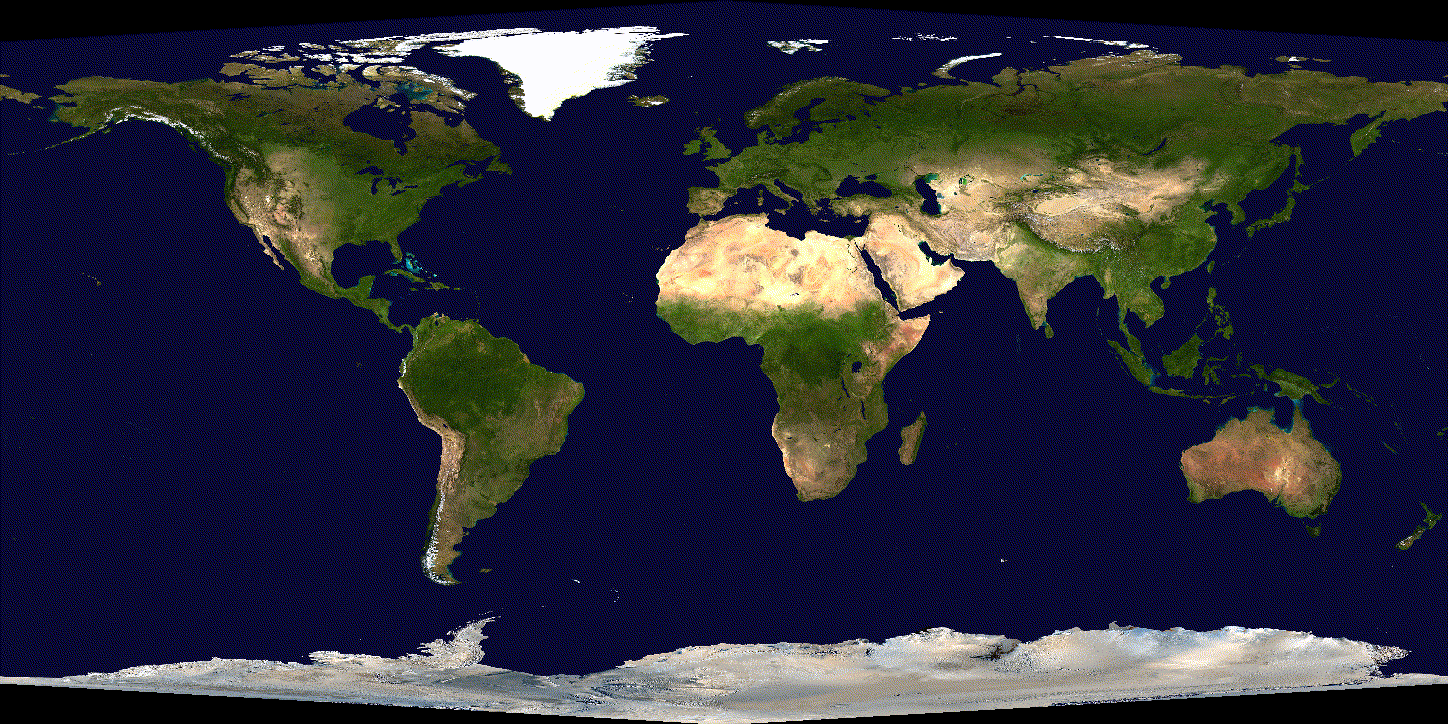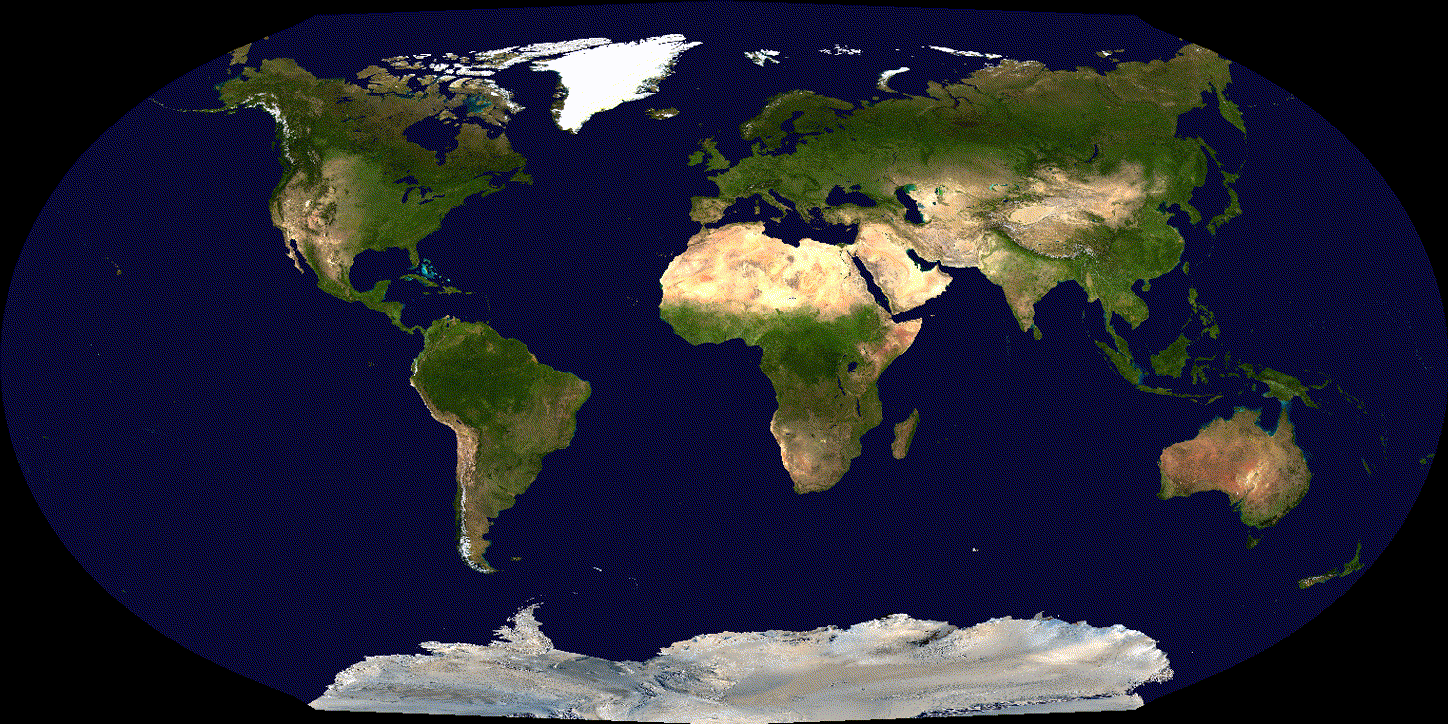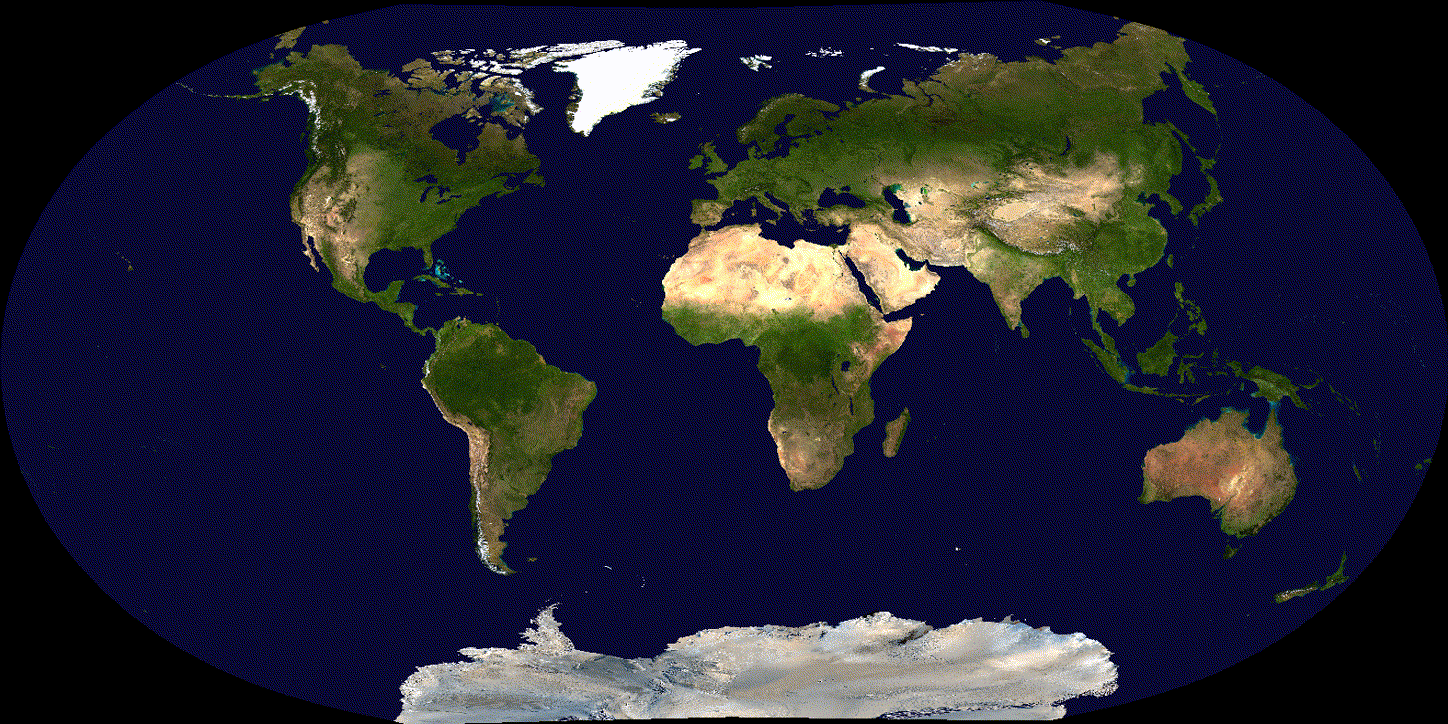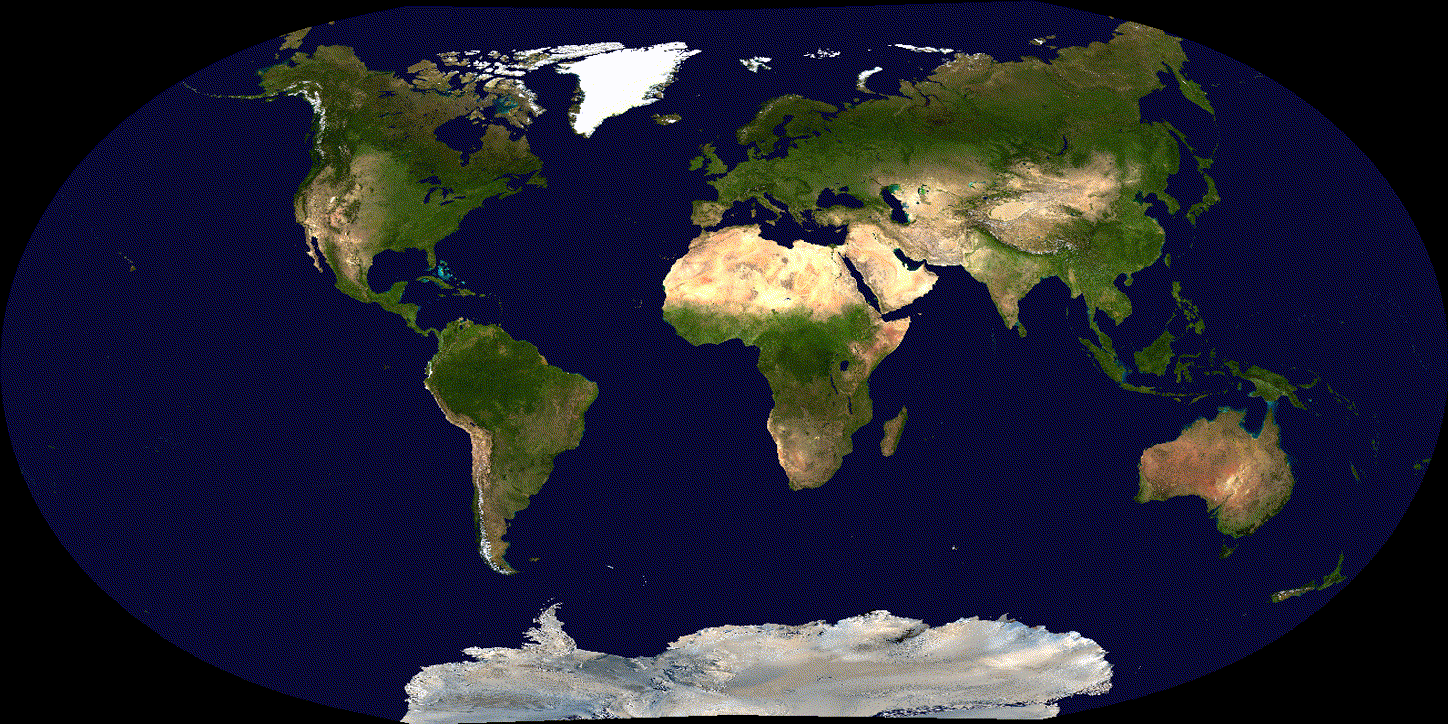 (Adam)
(Adam)
By the way, I'm using NASA's high resolution, true-color image of the Earth (confusingly named Blue Marble).
Software and Hardware
I implemented this in
JAX
and ran it on my Macbook Pro's M3 GPU
(edit 2024-02-22: I realized there's something horribly wrong with jax-metal,
the closed source library for using Apple silicon GPUs.
Removing it and using the CPU improved my performance a whopping 300x.).
The code is a mess right now, so I'll be making it available... later.
Along with the learned projections.
Related Work
At first I searched for similar approaches to optimize non-parametric map projections, but couldn't find any. It was only by chance that I saw a Reddit post leading me to Justin Kunimune's Danseiji and Elastic projections. As far as I know, this is the only similar approach to mine. He has his own software project and paper, with some similar and some different decisions made. I only discovered it at the tail end of my research when I had already decided on most of my own approach.
It's a very cool piece of work, and he has quite a broad range of maps.
His choice of L-BFGS is probably more efficient than gradient descent with Adam.
If I have one criticism, though, it's that the
Neo-hookean energy function
doesn't seem to have physical meaning here.
But I understand why he didn't choose the
the Airy-Kavrayskiy criterion,
which is similar to my loss function.
Instead of the convex loss , they use
 , royally screwing up any hopes of a balanced loss distribution over the globe.
, royally screwing up any hopes of a balanced loss distribution over the globe.
It's clear that Kunimune has some wisdom on this topic by now, saying
"With hindsight, I know that lenticular mesh-based projections (Danseiji N, I, and II) aren’t that good or interesting, and don’t gain you much you don’t already get from the Eckert or Györffy projections."
He's lost interest in the type of projection I'm making, but I am undeterred! In the next part, I'll start showing my results!
Map Projections 3: The Essential Results
Map Projections 4: Bullying the Oceans
Map Projections 5: More Interruptions