Graph all the things
analyzing all the things you forgot to wonder about
Startup Names
2017-12-31
interests: laughing about startups
It's a Silicon Valley pasttime to poke fun at startup culture - from awful startup idea generators to Business Town. I made a startup name generator based on an RNN that learns patterns from real startup names. Click the button to generate some:
Another fun way to enjoy this generator is by guessing which startup name is real and which is computer-generated, much like arXiv vs snarXiv:
Data Source
I scraped AngelList for startup names. They have a handy search tool for getting lists of startups, but cap results at 400. I created a script that ran queries for non-redundant combinations of ranges and options so that I could obtain as many startup names as possible. I ultimately obtained 22,721 usable startup names. You can find my code in this Github repo.
Out of these, I used 21,000 for training and 1,721 for validation. I cleaned the dataset by using only 40 characters: lowercase alphanumerics, hyphen, dot, space, and newline (the stop character indicating end of startup name). I also used NFKD to normalize unicode characters like "ü" to their ascii equivalents, removed groups of parentheses, and eliminated other oddities.
The Model
I used pytorch to create a fully recurrent neural network that guesses the next character after receiving a sequence of characters. The input layer was a one-hot vector of width 41 (the usual 40 characters, plus one indicating no data, or the start of the name), and the output was a softmax probability vector across the 40 characters. In between I had 3 layers, each with 150 relu-activated hidden units.
I trained the model for 35 epochs with a cosine learning rate schedule.
Ultimately the model learned to predict the validation data's next character 39.6% of the time, with an average log likelihood of -2.06 per character. This might not sound impressive, but it had to guess between 40 options for each character (so baseline accuracy of 2.5%, or apparently 9.2% if you always guess the most common character e), and I wager you would have a very hard time beating it. Here are some training plots:
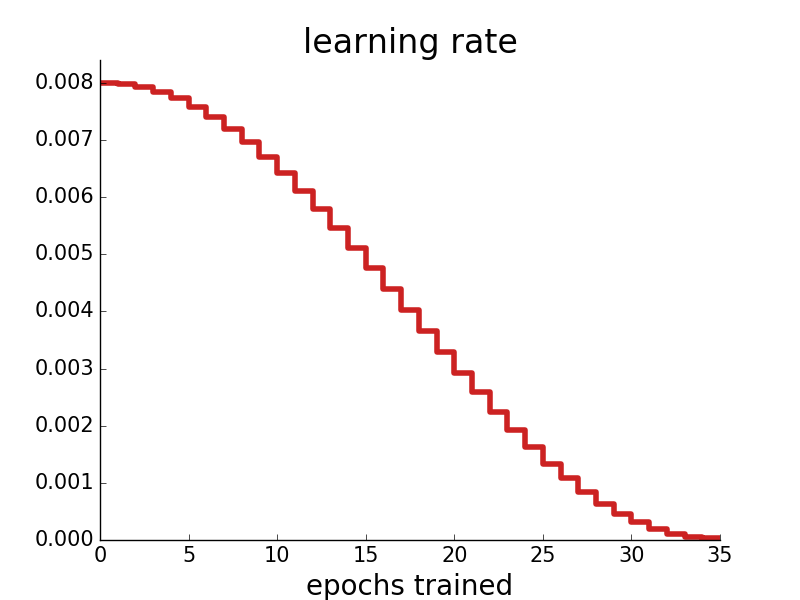
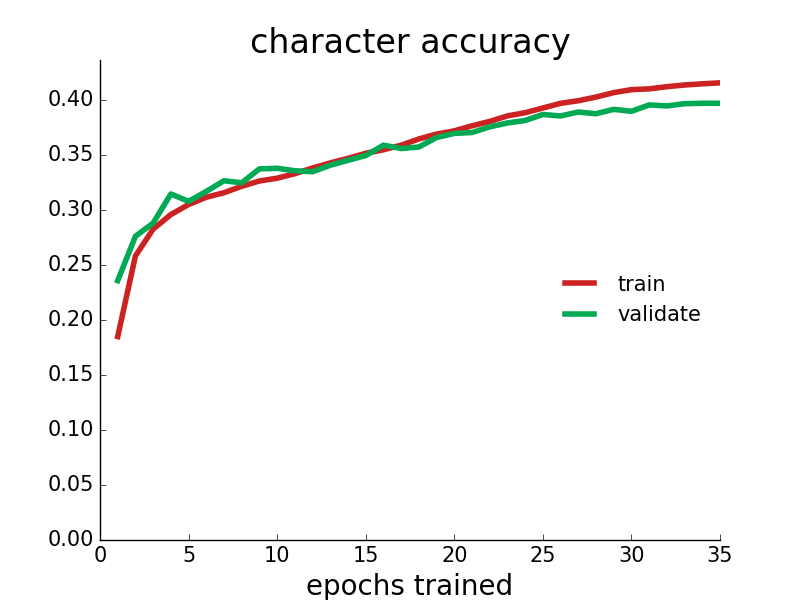
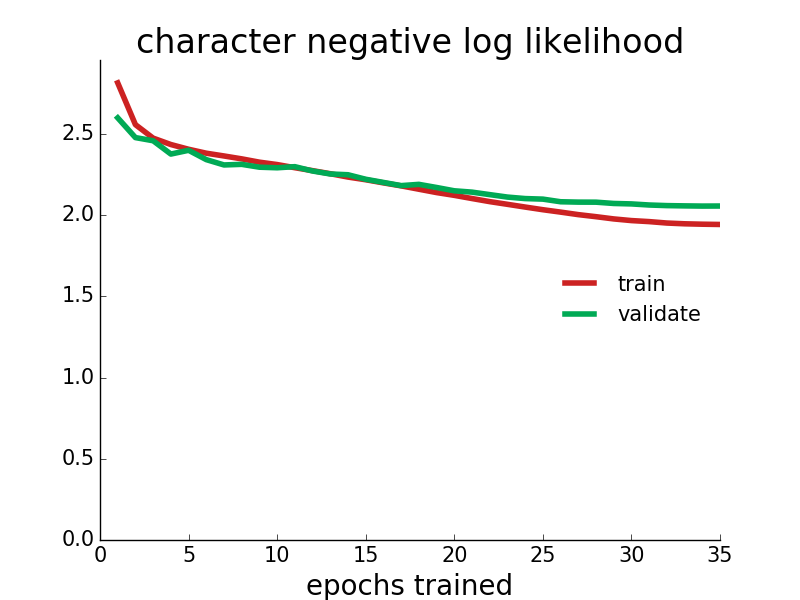
99.0% of startup names generated are original (not present in the training data). The guessing game above only uses original invented startup names, in case you were wondering.
The most startup name of all
The names you can play with above are generated character-by-character, each time choosing a character at random based on the network's output probabilities. However, using a greedy approach by choosing the character with the greatest probability every time, yields arguably the most startup name of all:
Update: 2018-01-27
I ran some breadth-first searches to calculate the truly most probably startup names. Without any restrictions, I got
Limiting to only names that aren't in the English dictionary, I got
And limiting to only original startup names (since realytics and some others actually exist), I got
¯\(ツ)/¯