Graph all the things
analyzing all the things you forgot to wonder about
Streaming Asymmetric Numeral System Explained
2023-09-10
interests: compression (explained for beginners)
A few months ago, I spent several hours struggling to understand the inner workings of a lossless compression technique called Tabled Asymmetric Numeral System (tANS). I couldn't find any good* explanations for the leap involved from vanilla ANS to streaming ANS, so I vowed to create one.
What are we compressing?
Symbols!
As a silly example, say we want to compress the words "freer reef referee referrer" where each letter is a symbol (ignoring spaces). There are 3 distinct symbols - "e", "f", and "r" (an alphabet size of 3), and 24 symbols total.
In practice, symbols have a slightly higher-level meaning. The classic DEFLATE format (e.g. gzip) uses 288 distinct symbols: 256 for all literal bytes, 29 meaning "look back at earlier symbols and copy some", 1 for the end of the data block, and 2 for unimplemented purposes. Pco compresses numbers by binning them, and it represents each bin as a symbol.
How are we compressing the symbols?
Turning them into a really big number!
Well, technically two numbers: one regular-size number  , say up to
, say up to  , encoding the total number of symbols, followed by the really big number
, encoding the total number of symbols, followed by the really big number  .
In this way we can spend
.
In this way we can spend  bits to compress the data.
If the compressed data ends up being a gigabit, will end up being about
bits to compress the data.
If the compressed data ends up being a gigabit, will end up being about  .
.
Vanilla ANS
If a symbol has frequency  in the data, we hope to spend about
in the data, we hope to spend about  bits to encode the character.
For example, if we have 2 equally frequent symbols, we expect to spend about 1 bit per symbol.
If we have 8 equally frequent symbols, we expect to spend about 3 bits per symbol.
In practice, each symbol will have its own arbitrary frequency, so we'd like to spend more bits per uncommon symbol and fewer bits per common one.
bits to encode the character.
For example, if we have 2 equally frequent symbols, we expect to spend about 1 bit per symbol.
If we have 8 equally frequent symbols, we expect to spend about 3 bits per symbol.
In practice, each symbol will have its own arbitrary frequency, so we'd like to spend more bits per uncommon symbol and fewer bits per common one.
We start by making a small table of symbols approximately mimicking the frequency of each symbol. In our silly example above, we might choose a table of "eefr" since "e" is a bit more common than the other symbols. Then we tile it infinitely along the number line (here I'm just using colored circles for the correspondingly colored letters):

Vanilla ANS's compression algorithm is dead simple: start with  , and when we encode the
, and when we encode the  th symbol, let
th symbol, let  be the index at which the
be the index at which the  st instance of that symbol occurs in the (tiled) table.
We use 0-based indexing so that the 0th instance really means the first.
The final
st instance of that symbol occurs in the (tiled) table.
We use 0-based indexing so that the 0th instance really means the first.
The final  is our really big number .
is our really big number .
Let's do an example, compressing the first 2 symbols "f" and "r".
Since and the first symbol is "f", we set  , where the 0th (first) "f" appears in the table:
, where the 0th (first) "f" appears in the table:

Then, since and the second symbol is "r", we set  where the 2nd (third) "r" appears in the table:
where the 2nd (third) "r" appears in the table:

It's also simple to decode: starting from  , iteratively decode the symbol at and let
, iteratively decode the symbol at and let  be the number of times that symbol appeared in the table up to (but not including) .
In the example above, we can start from , see that 11 corresponds to an "r", and infer since 11 is the third instance of an "r".
Then we can use to infer the previous symbol was "f" and so forth.
be the number of times that symbol appeared in the table up to (but not including) .
In the example above, we can start from , see that 11 corresponds to an "r", and infer since 11 is the third instance of an "r".
Then we can use to infer the previous symbol was "f" and so forth.
Since half the symbols in our table are "e", each time we encode an "e" we roughly double , adding one bit.
And each time we encode an "f" or "r" we roughly quadruple , adding two bits.
With a larger table, we could get closer to the ideal number of bits ( per "e", 2.58 per "f", and 1.43 per "r").
per "e", 2.58 per "f", and 1.43 per "r").
To summarize vanilla ANS in a single diagram:

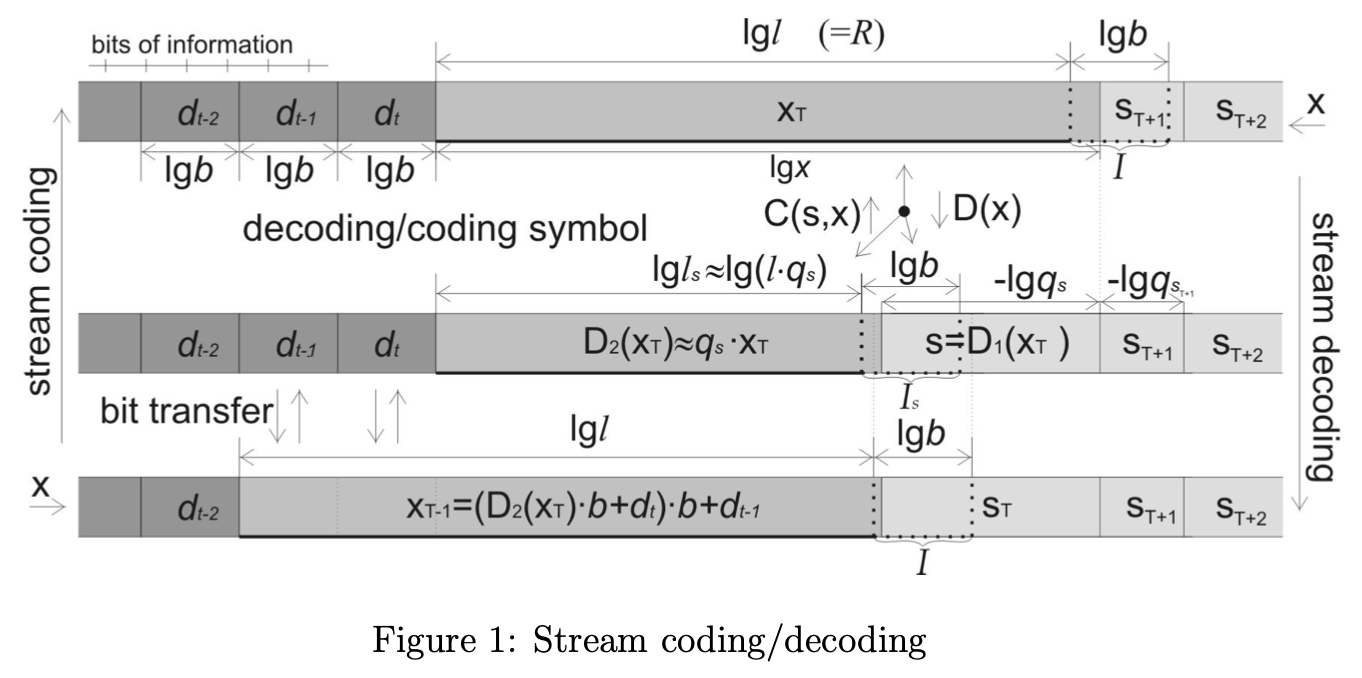
Streaming and normalization
Vanilla ANS is great and easy to understand, but it's impractical because it involves arithmetic on an extremely large integer .
To make it faster and more memory-efficient, we need a way to keep small.
We do this by adding a step to encoding called normalization, and a corresponding step to decoding called denormalization (sometimes these are both called "renormalization", but that seems redundant and ambiguous to me):

Normalization and denormalization keep in a manageable range by writing bits out early instead of letting grow arbitrarily large.
In particular, we require the table size  to be a power of 2, and we keep in the interval
to be a power of 2, and we keep in the interval  .
Emitting bits early like this sacrifices a small amount information during normalization, hurting compression ratio a smidgen, but spares us from doing impractical arithmetic.
.
Emitting bits early like this sacrifices a small amount information during normalization, hurting compression ratio a smidgen, but spares us from doing impractical arithmetic.
Here's the main thing that tripped me up learning streaming ANS: I thought it would be equivalent to a special case of vanilla ANS with a  -sized table.
This is not the case.
Normalization has no vanilla ANS analog, and it reduces the precision of , regardless of table size.
-sized table.
This is not the case.
Normalization has no vanilla ANS analog, and it reduces the precision of , regardless of table size.
To normalize when compressing a symbol, we count  , the number of times the symbol appears in the table, then find the exponent
, the number of times the symbol appears in the table, then find the exponent  such that
such that  .
We write out the least significant bits of to the bitstream, then return
.
We write out the least significant bits of to the bitstream, then return  as the value of normalized to the symbol.
Normalization is complete, and we then apply the vanilla ANS step to
as the value of normalized to the symbol.
Normalization is complete, and we then apply the vanilla ANS step to  , giving
, giving  .
.
If you think about it, must be in the interval , since it's the index of the th occurrence of the symbol in the table and is between 1- and 2-times the number of occurences of the symbol in the table.
Denormalization is just the opposite.
After undoing vanilla ANS, we get both and the symbol, and then we can find the exponent such that  .
We read those least significant bits back from the bitstream and get
.
We read those least significant bits back from the bitstream and get  .
.
Normalization isn't magic, but it satisfies 3 important properties:
- It's invertible. (necessary to get the symbols back)
- It returns an such that vanilla ANS applied to is in a fixed range. (improves compression/decompression speed and memory usage)
- It carries the most significant information from into . (doesn't hurt compression ratio too much)
Range Asymmetric Numeral System (rANS)
This is just a name for the streaming algorithm described in the previous section. Done!
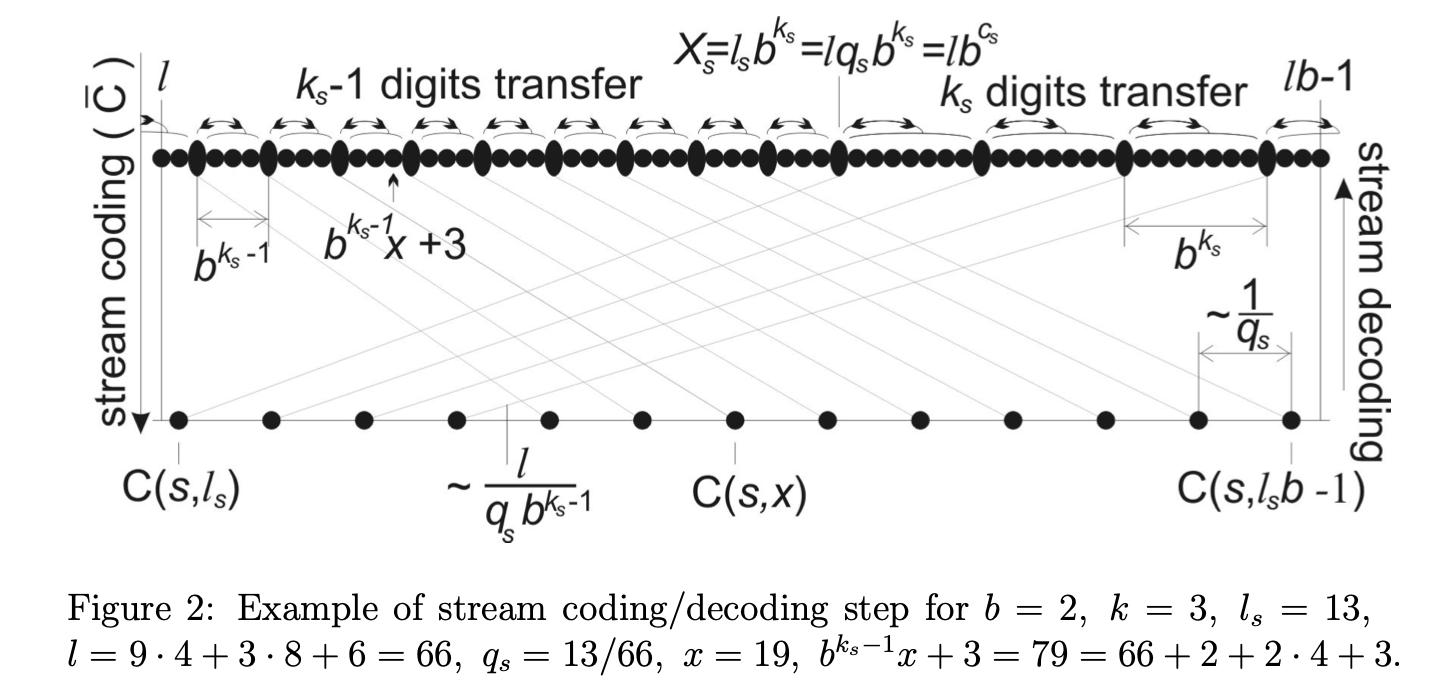
Tabled Asymmetric Numeral System (tANS)
Finding the value of used during normalization and denormalization on the fly can be expensive.
It also affects the number of bits you need to write/read, so CPUs need to block on evaluating before evaluating the next steps.
It can be faster to precompute the information needed for all states of the table.
For instance, in the decoder, we can make a table from every in the normalized range to
- its symbol,
- how many more bits to read for denormalization,
- and the next value of to add the least significant bits to.
This is equivalent to rANS, but is usually faster when the size of the data is much larger than the table.
Confusing thing explained: decoding doesn't have enough options?
In our "eefr" example with streaming, "e" has 2 occurrences in a table of size 4, so every time we denormalize after an "e" during decoding we read exactly 1 bit. So, based on the bitstream, the decoder is choosing between at most 2 symbols to decode next! What if the next symbol is supposed to be the 3rd one though? If we had swapped that next symbol with the 3rd one during compression, how could the decoder possibly decode it?
The trick is that compression was done in the opposite order.
It's exactly like the movie Tenet (wait a sec, that won't help anyone understand...).
To the decoder, we're talking about the next symbol, but to the encoder, it's the previous symbol.
If we swap the th symbol out for  during compression, we'd end up in a different state that does have the option to decode .
during compression, we'd end up in a different state that does have the option to decode .
One way of thinking about it: the encoder and decoder each encounter a choice at every symbol.
The compressor always has exactly one option per symbol in the alphabet, but the decoder may have more or fewer.
Notice that every state has an out-edge (encoding option) of each symbol, but doesn't necessarily have in in-edge (decoding option) for each symbol:

More reading material
I've skipped over some of the canonical commentary about ANS (e.g. that either compression or decompression needs to be done in reverse order; how ANS compares to Huffman codes; choosing and encoding the table), but other guides cover that decently already. It's worth noting that the research on ANS came out only about a decade ago, so I'm sure learning materials are still improving.
- original paper (Jarek Duda)
- a good blog post about ANS with some interactivity (Kedar Tatwawadi)
- various blog posts about ANS implementation details (Fabien Giesen)
- Wikipedia
Footnotes
* Jarek Duda, the author of ANS, is brilliant, but his diagrams don't make any damn sense to me: