Graph all the things
analyzing all the things you forgot to wonder about
Map Projections 1: Not Solving Exactly
2023-09-28
interests: differential geometry, PDEs
I looked into whether it's mathematically possible to solve for an optimal map projection. That is - find a smooth bijective function from the sphere to a subset of the plane that minimizes the integral of a local loss function. The short answer: not for any interesting cases. I did solve one contrived example, though.
I'm saving the fun visualizations and flavor text for later posts. This one is just hard math.
Turning the optimization into a PDE
Every map projection can be thought of us a function  from spherical coordinates
from spherical coordinates  to euclidean coordinates
to euclidean coordinates  (I'm using
(I'm using  and
and  instead of
instead of  and
and  to avoid some confusion later).
Unfortunately, there's no perfect map projection that preserves both angles and area.
All you can do is preserve one of these and keep the other one under control.
Or you can forsake both and strike a compromise.
to avoid some confusion later).
Unfortunately, there's no perfect map projection that preserves both angles and area.
All you can do is preserve one of these and keep the other one under control.
Or you can forsake both and strike a compromise.
I thought about choosing a map projection as minimizing a local loss function integrated over the globe:

 are spherical coordinates,
are spherical coordinates, is a differentiable function from
is a differentiable function from  to the plane,
to the plane, is the Jacobian of
is the Jacobian of  ,
, is a smooth function for local loss given a Jacobian
is a smooth function for local loss given a Jacobian  , and
, and is a weight function to account for the local surface area of the sphere.
is a weight function to account for the local surface area of the sphere.
From here on, I'll be dropping arguments and letting be the Jacobian .
Optimizing a single parameter in  is intuitive.
is intuitive.
Optimizing a function from  gets more interesting.
gets more interesting.
Optimizing a function from  is utterly confusing in my opinion.
I worked out the following derivation.
is utterly confusing in my opinion.
I worked out the following derivation.
A necessary condition for an optimal map projection is that applying a perturbation to it will not decrease the loss.
If  is a smooth perturbation to
is a smooth perturbation to  ,
,

 ,
,

 , I mean "the gradient of
, I mean "the gradient of  with respect to the th column vector of its Jacobian argument.
Using generalized integration by parts with
with respect to the th column vector of its Jacobian argument.
Using generalized integration by parts with  and
and  as the parts, this turns into
as the parts, this turns into

 can be absolutely anything, the only way to satisfy this equation for all choices of is to make the rest of the integrands 0 everywhere:
can be absolutely anything, the only way to satisfy this equation for all choices of is to make the rest of the integrands 0 everywhere:

 's Jacobian, not to changes in
's Jacobian, not to changes in  , but the message is clear: if there were a sink, we could "move" some of into the sink (i.e. reduce in some places and increase it in others) to reduce loss.
, but the message is clear: if there were a sink, we could "move" some of into the sink (i.e. reduce in some places and increase it in others) to reduce loss.
Equation (2) specifies what the boundary of the projection should look like. Its interpretation is something like "when weight is nonzero, the gradient of loss with respect to the Jacobian must be perpendicular to the boundary". We must not be able to decrease loss by stretching the edges of the map projection in any direction.
This derivation reminds me a lot of Lagrangian mechanics. And there is certainly a differential geometry interpretation here, but I can't be bothered to sort it out.
But (1), the PDE, is quite troublesome.
Choose pretty much any loss function, and it becomes utterly intractible.
I will argue in a future blog post that the loss should be based on the singular values of , and simply expressing the demonic PDE arising from that is not worth anyone's time.
Instead, I'll solve a contrived example.
The contrived example
Finding a nontrivial solution to even (1) alone is hard, so instead I'll find a solution to (1) with a suboptimal boundary, not solving (2), using a simple loss function with a no-so-simple boundary condition.
Suppose we have this dumb  loss:
loss:

 , the equirectangular projection.
This projection's only merit is its mathematical simplicity.
, the equirectangular projection.
This projection's only merit is its mathematical simplicity.
But with the newfound derivation above, we can hunt for an optimal projection under this loss with a non-rectangular shape.
Starting from (1), plugging everything in, and skipping the intermediate work, we get a PDE for each of  and
and  :
:


 ,
,  ,
,  ):
):


 ,
,  ,
,  and plotting between
and plotting between  latitude gives this:
latitude gives this:
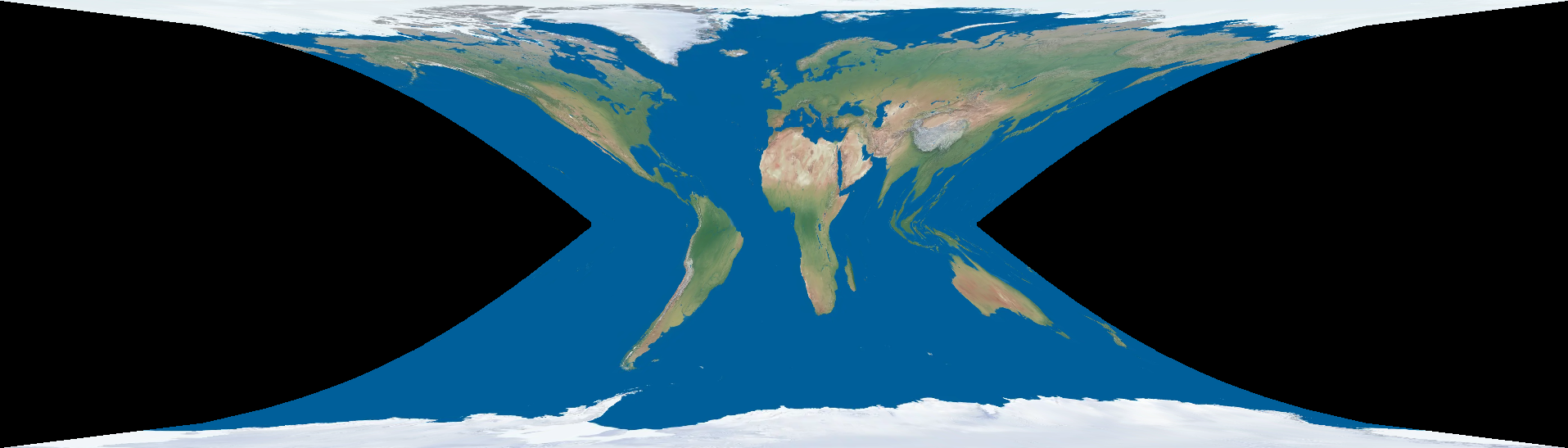
So... yeah, we have a map projection that's optimal (by a silly definition) everywhere (except the ridiculous boundary). In that very lame sense, we can exactly solve some optimal map projections.
In future parts, I'll look at the more interesting technique of solving optimal map projections numerically.
Map Projections 2: Solving Numerically
Map Projections 3: The Essential Results
Map Projections 4: Bullying the Oceans
Map Projections 5: More Interruptions