Graph all the things
analyzing all the things you forgot to wonder about
President Rankings
2017-05-11
interests: US history, unsupervised learning, interactive visualizations
Some historians find it fun to rank presidents, and they do this regularly in the Sienna Research Institute Presidents Study, ranking all past presidents on 20 different criteria. I noticed that the rankings are heavily redundant. Just look at "overall ability" versus "executive ability" - that's 96% correlation! To make a bit more sense of this 20-dimensional data (a ranking for each category for each president), I plotted each president's rankings in 20-dimensional space, then rotated and recentered them so that the axes line up with the directions the data varies in.
Click on a president to follow him, and compare different axes!
This is called Principal Component Analysis (PCA). The resulting dimensions are ranked from most to least descriptive, and the first (most descriptive) one is called the principal component.
My takeaways from this are:
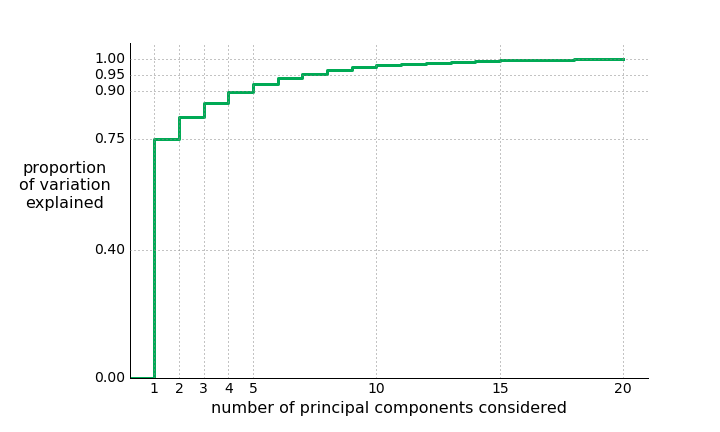
- The most descriptive quality for a president is how good they generally were. This axis alone explains 75% of the dataset's variation.
- The 2nd most descriptive quality for a president is how much more redeeming their qualities were than their successes.
- The 3rd most descriptive quality for a president is the extent to which they made cautious (and ethical) decisions without collaboration/leadership.
- The 4th most descriptive quality for a president is the extent to which they made cautious decisions with collaboration/leadership.
- Any components after that are either too hard to interpret or basically just noise; the remaining 16 only constitute 10% of the dataset's variation. Perhaps these first 4 components are the only true criteria we should bother asking historians.
- Lyndon B. Johnson is the most interesting president.
Here's the proportion of the data that's conveyed by the first  components:
components:
Math and Intuition for PCA
This part relies on knowledge of covariance and basic linear algebra.
Let  be a random variable in
be a random variable in  with
with  covariance matrix
covariance matrix  (in this case,
(in this case,  and the variables are the rankings, so the covariance is Spearman's rank covariance). The principal components of the probability distribution are the normalized eigenvectors
and the variables are the rankings, so the covariance is Spearman's rank covariance). The principal components of the probability distribution are the normalized eigenvectors  of . They have important properties that make PCA meaningful:
of . They have important properties that make PCA meaningful:
- The most descriptive component is the one with the largest corresponding eigenvalue. In general, the eigenvalue
 corresponding to
corresponding to  is the variance of the distribution of
is the variance of the distribution of  in the direction of ; that is,
in the direction of ; that is, ![\lambda_i = \text{Var}[v_i \cdot X]](/latex/3f08b08a0a17094d5bc2de83456196ba.svg) . This gives a nice easy way to rank the components from most to least descriptive.
. This gives a nice easy way to rank the components from most to least descriptive. - The principal components are uncorrelated;
![\text{Cov}[v_i\cdot X, v_j\cdot X] = 0](/latex/2e0f313b08763726e768073accab876e.svg) for
for  . This is what makes the data appear to line up with the axes.
. This is what makes the data appear to line up with the axes.
In fact, PCA can be derived from that last bullet. If you remember some basic formulas for covariance,
![\text{Cov}[v_i\cdot X, v_j\cdot X] = \sum_{k=1}^n\sum_{l=1}^nv_{ik}v_{il}\text{Cov}[X_k, X_l]](/latex/c214417ee5c3196d9d0d457b4543a519.svg)
![\text{Cov}[v_i\cdot X, v_j\cdot X] = \sum_{k=1}^n\sum_{l=1}^nv_{ik}v_{il}A_{kl}](/latex/a042243e49e1b888fb6c46ae5ff2a8dd.svg)
![\text{Cov}[v_i\cdot X, v_j\cdot X] = v_i^TAv_j](/latex/f1a190a72719d9fc9cd5a87765e9ebf0.svg) for , the uncorrelated components we are looking for must be orthogonal under the covariance matrix . Since all covariance matrices are positive definite, that condition is uniquely satisfied (up to scaling) by the eigenectors of . And if we use the normalized eigenvectors, we get
for , the uncorrelated components we are looking for must be orthogonal under the covariance matrix . Since all covariance matrices are positive definite, that condition is uniquely satisfied (up to scaling) by the eigenectors of . And if we use the normalized eigenvectors, we get
![\text{Var}[v_i\cdot X] = v_i^TAv_i](/latex/22e7c1e0a457a07b66753bf49065070e.svg)
![\text{Var}[v_i\cdot X] = \lambda_iv_i^Tv_i](/latex/121607459e5316b3384e4ee0c9ec1e5c.svg)
![\text{Var}[v_i\cdot X] = \lambda_i](/latex/fec47c962f3dcb2be47744f1845ce45b.svg)